
The State Library of South Australia will trial the use of Digital Collections (Recollect product) to produce electronically searchable transcriptions of diaries. The application provides a range of opportunities that the previous manual methods of transcription couldn’t.
In particular, transcribing from diaries that are digitised and on Digital Collections will:
- Significantly reduce of the risk of damage or loss when using originals
- Images can be enlarged to assist deciphering of text
- Transcribed text matches the page of the diary being viewed
- Transcripts can be searched throughout the Digital Collections site
As the transcription furthers the opportunities for searchability and discovery, SLSA is looking to embrace opportunities that enable online and computational discovery.
To build on the decades of digital collection practice, SLSA acknowledges the developing requirement to manage collections as data, along with its existing traditional methods. The idea of collections as data is a “conceptual orientation to collections that renders them as ordered information, stored digitally, that are inherently amendable to computation” < href=”https://collectionsasdata.github.io/”>(Always already computational: Collections as data Final Report 2018).
In this way, the content of transcriptions can be offered as data sets to be further mined by researchers on a large scale. The trial will also assist in identifying requirements and specifications for a potential dedicated Transcription tool.
SLSA’s alignment with the North Terrace Cultural Precinct Innovation Lab and previous management of the Unleashed Open Data (GovHack) competitions have been the indicators of how SLSA will
treat its collections.
For these reasons, SLSA will introduce some structure to the transcription process that will assist with computational discovery.
While it would be beneficial for all possible entry points such as names, dates, places etc to be fully indexed, it is not practical to expect volunteers to undertake this work.
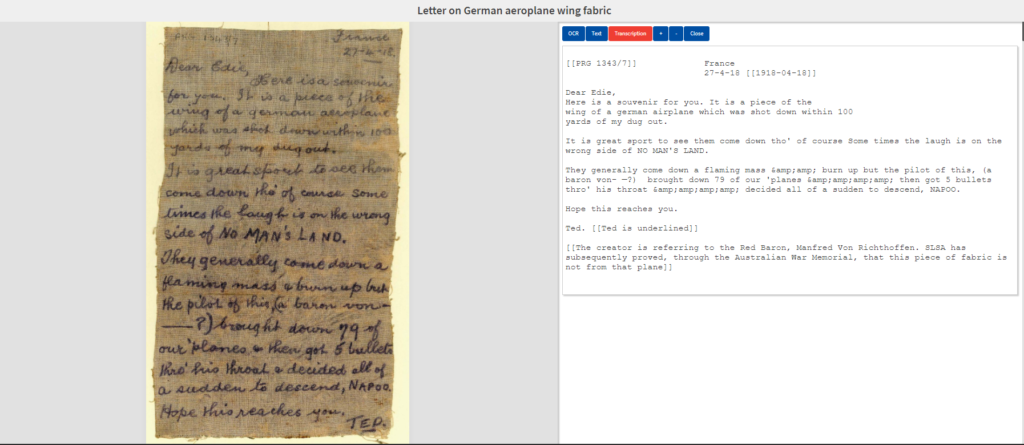
The issue of consistency is the major problem associated with metadata and stands in the way of data discovery and re-usability. Following discussions with professional and student representatives of the School of Mathematical Sciences, University of Adelaide, who have used war diaries from the State Library of New South Wales, one of the most significant challenges was with the computational requirements surrounding dates and the myriad ways these are written in diaries.
Dates also provide a way of discovery for an event where any event is prone to the use of vernacular and may vary from writer to reader – e.g. World War 1 was contemporarily referred to as the European War.
To overcome this and provide an international recognised way of recording dates within transcriptions is to reproduce the date according to ISO 8601 Date and time format as a transcribers notes. This standardisation also conforms to W3C requirements. For example 27 September 2021 represents as 2012-09-27.
We are still exploring ways to capture transcriber’s notes into the text that will be clear when performing searches across the data, are clearly transcribers notes and not part of the original text. Current thinking is to use [[ ]] or << >> and initial tests have shown that, unless the html is turned off behind the scenes, the << >> will remove the text.
We continue to investigate, hoping to identify a sequence of characters that are reasonably neutral, yet provide a clear visual representation when read by humans.
It is clear that when we do finally release the data, we will need to have clear descriptions of the data so that any business practices we have adopted can be countered for when researchers attempt computational practices across our data.